在python中调用selenium,访问百度,并运行js脚本爬取内容
python入口程序
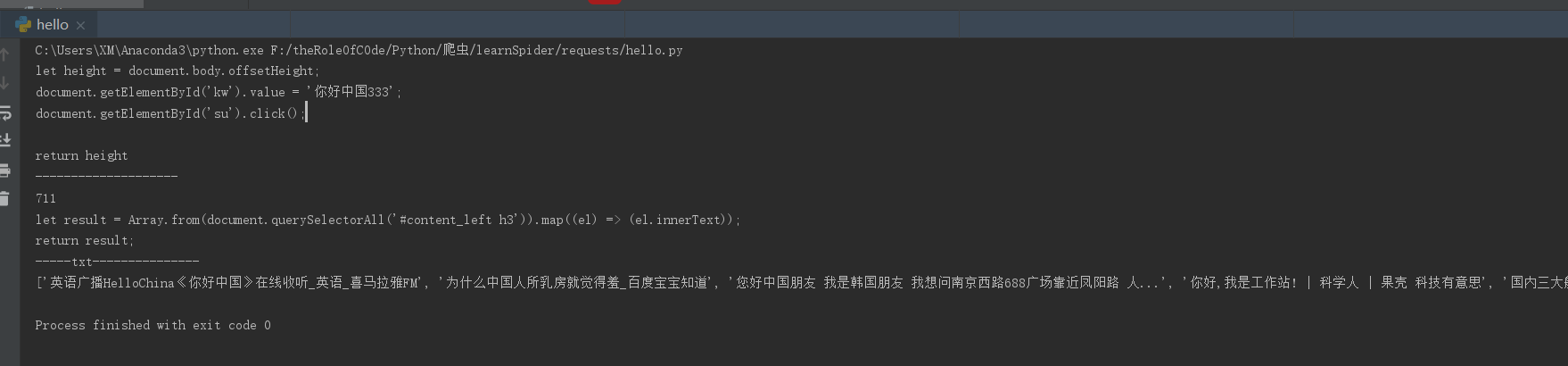
from selenium import webdriverimport timewith open('./test.js', 'r',encoding='utf-8',errors='ignore') as f: str = f.read()print(str)brower = webdriver.Chrome()brower.maximize_window() # 最大化浏览器brower.get("https://www.baidu.com") # 通过get()方法,打开一个url站点time.sleep(3)clientWidth = brower.execute_script(str)print('--------------------')print(clientWidth)with open('./test2.js', 'r',encoding='utf-8',errors='ignore') as f: str2 = f.read()print(str2)time.sleep(4)txt = brower.execute_script(str2)print('-----txt---------------')print(txt) test1.js
let height = document.body.offsetHeight;document.getElementById('kw').value = '你好中国333';document.getElementById('su').click();return height test2.js
let result = Array.from(document.querySelectorAll('#content_left h3')).map((el) => (el.innerText));return result;